# 5. 最长回文子串
力扣原题链接(点我直达) (opens new window)
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: "babad"
输出: "bab"
注意: "aba" 也是一个有效答案。
2
3
示例 2:
输入: "cbbd"
输出: "bb"
2
# 第一版,中间向外扩展法,自己写的
执行用时 :124 ms, 在所有 cpp 提交中击败了47.66%的用户
内存消耗 :46.8 MB, 在所有 cpp 提交中击败了32.27%的用户
void Substrings(string &s,string &longestStr,int i,int j) {
string left = "", right = "";
if (i == j) {
right += s[j++];
i--;
}
while ( i>=0 && j<s.size() && s[i]==s[j]) {
left +=s[i--];
right+=s[j++];
}
if (left.size() + right.size() > longestStr.size()) {
reverse(left.begin(), left.end());
longestStr = left + right;
}
}
string longestPalindrome(string s) {
if (s.size() <= 1) return s;
string longestStr = "";
for (int i = 0; i < s.size(); ++i) {
Substrings(s, longestStr, i, i);
Substrings(s, longestStr, i, i+1);
if (longestStr.size() == s.size()) break;//自身就是个回文子串,直接break就行
}
return longestStr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 第二版,标准DP解法
执行用时 :244 ms, 在所有 cpp 提交中击败了29.93%的用户
内存消耗 :18.9 MB, 在所有 cpp 提交中击败了39.03%的用户
string longestPalindrome(string s) {
if (s.size() <= 1) return s;
int n = s.size(),low=0,high=0,longLen=0;
vector<vector<bool>> dp(n, vector<bool>(n, false));
for (int i = n-1; i >=0; --i) {
for (int j = i; j < n; ++j) {
if (s[i] == s[j] && (j - i <= 1 || dp[i + 1][j - 1])) {
dp[i][j] = true;
if (j - i > longLen) {
longLen = j - i;
low = i;
high = j;
}
}
}
}
string longestStr = "";
while (low <= high)
longestStr += s[low++];
return longestStr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 62. 不同路径
力扣原题链接(点我直达) (opens new window)
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
问总共有多少条不同的路径?
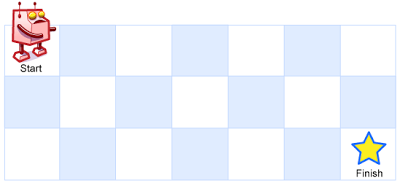
例如,上图是一个7 x 3 的网格。有多少可能的路径?
**说明:**m 和 n 的值均不超过 100。
示例 1:
输入: m = 3, n = 2
输出: 3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
1. 向右 -> 向右 -> 向下
2. 向右 -> 向下 -> 向右
3. 向下 -> 向右 -> 向右
2
3
4
5
6
7
示例 2:
输入: m = 7, n = 3
输出: 28
2
# 第一版本,常规解法
执行用时 :8 ms, 在所有 cpp 提交中击败了16.66%的用户
内存消耗 :8.7 MB, 在所有 cpp 提交中击败了12.43%的用户
int uniquePaths(int m, int n) {
vector<vector<int>>dp(m,vector<int>(n,0));
for (int i = 0; i < m; ++i) {
dp[i][0] = 1;
}
for (int j = 0; j < n; ++j) {
dp[0][j] = 1;
}
for (int i = 1; i < m; ++i) {
for (int j = 1; j < n; ++j) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 第二版,改进一下速度
执行用时 :0 ms, 在所有 cpp 提交中击败了100.00%的用户
内存消耗 :8.7 MB, 在所有 cpp 提交中击败了10.72%的用户
int uniquePaths(int m, int n) {
vector<vector<int>>dp(m,vector<int>(n,0));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (i == 0 || j == 0) dp[i][j] = 1;
else
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
# 63. 不同路径 II
力扣原题链接(点我直达) (opens new window)
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
网格中的障碍物和空位置分别用 1 和 0 来表示。
**说明:**m 和 n 的值均不超过 100。
示例 1:
输入:
[
[0,0,0],
[0,1,0],
[0,0,0]
]
输出: 2
解释:
3x3 网格的正中间有一个障碍物。
从左上角到右下角一共有 2 条不同的路径:
1. 向右 -> 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右 -> 向右
2
3
4
5
6
7
8
9
10
11
12
# 第一版
执行用时 :4 ms, 在所有 cpp 提交中击败了90.82%的用户
内存消耗 :9.5 MB, 在所有 cpp 提交中击败了5.32%的用户
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
if(obstacleGrid[0][0]==1) return 0;
int m = obstacleGrid.size(), n = obstacleGrid[0].size();
vector<vector<uint64_t>> res(m, vector<uint64_t>(n, 0));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (obstacleGrid[i][j] == 1) continue;
if (i == 0 && j == 0) res[i][j] = 1;
else if(i==0) res[i][j]=res[i][j-1];
else if(j==0) res[i][j]=res[i-1][j];
else
res[i][j] = res[i - 1][j] + res[i][j - 1];
}
}
return res[m - 1][n - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
第一行第一列数据初始化的时候就不能都是1了,因为有的地方有障碍物存在。
如果起始位置就是障碍的话,哪里也去不了了
# 64. 最小路径和
力扣原题链接(点我直达) (opens new window)
给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
**说明:**每次只能向下或者向右移动一步。
示例:
输入:
[
[1,3,1],
[1,5,1],
[4,2,1]
]
输出: 7
解释: 因为路径 1→3→1→1→1 的总和最小。
2
3
4
5
6
7
8
# 第一版,自己写的,会很多了
执行用时 :8 ms, 在所有 cpp 提交中击败了93.27%的用户
内存消耗 :10.8 MB, 在所有 cpp 提交中击败了63.77%的用户
int minPathSum(vector<vector<int>>& grid) {
if (grid.empty()) return 0;
if (grid[0].empty()) return 0;
int m = grid.size(), n = grid[0].size();
vector<vector<int>> res(m, vector<int>(n, 0));
res[0][0] = grid[0][0];
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; j++) {
if (i == 0 && j == 0) res[i][j] = grid[0][0];
else if (i == 0) res[i][j] += res[i][j - 1]+grid[i][j];
else if (j == 0) res[i][j] += res[i - 1][j] + grid[i][j];
else res[i][j] += min(res[i - 1][j], res[i][j - 1]) +grid[i][j];
}
}
return res[m - 1][n - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 72. 编辑距离 非常经典的DP问题
力扣原题链接(点我直达) (opens new window)
给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入: word1 = "horse", word2 = "ros"
输出: 3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')
2
3
4
5
6
示例 2:
输入: word1 = "intention", word2 = "execution"
输出: 5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')
2
3
4
5
6
7
8
# 第一版,别人的解法
# 第一种解答
求解编辑距离,也是经典老题,编辑距离其实在实际工作中也会用到,主要用于分析两个单词的相似程度,两个单词的编辑距离越小证明两个单词的相似度越高。
题目说可以通过增加字符,删除字符,以及 替换字符 这三个操作来改变一个字符串,并且每个操作的 cost 都是 1,问一个单词转换成另一个单词的最小 cost,老样子,四个步骤分析一遍:
问题拆解
我们考虑求解 str1(0…m) 通过多少 cost 变成 str2(0…n),还是来看看它的子问题,其实还是三个
str1(0…m-1) 通过多少 cost 变成 str2(0…n)
str1(0…m) 通过多少 cost 变成 str2(0…n-1)
str1(0…m-1) 通过多少 cost 变成 str2(0…n-1)
你可能会问你怎么这么快就写出子问题来,这些子问题是如何推导来的,它们和当前问题之间的联系又是什么?
别急,听我慢慢道来。
一般字符匹配类问题的核心永远是两个字符串中的字符的比较,而且字符比较也只会有两种结果,那就是 相等 和 不相等,在字符比较的结果之上我们才会进行动态规划的统计和推导。
回到这道题,当我们在比较 str1(m) 和 str2(n) 的时候也会有两种结果,即 相等 或不相等,如果说是 相等,那其实我们就不需要考虑这两个字符,问题就直接变成了子问题 str1(0…m-1) 通过多少 cost 变成 str2(0…n-1),如果说 不相等,那我们就可以执行题目给定的三种变换策略:
将问题中的 str1 末尾字符 str1(m) 删除,因此只需要考虑子问题 str1(0…m-1),str2(0…n)
将问题中的 str1 末尾字符 str1(m) 替换 成 str2(n),这里我们就只需要考虑子问题 str1(0…m-1),str2(0…n-1)
将问题中的 str1 末尾 添加 一个字符 str2(n),添加后 str1(m+1) 必定等于 str2(n),所以,我们就只需要考虑子问题 str1(0…m),str2(0…n-1)
如果你还不是特别清楚问题之间的关系,那就画图表吧,这里我就略过。
状态定义
dp[i][j] 表示的是子问题 str1(0…i),str2(0…j) 的答案,和常规的字符匹配类动态规划题目一样,没什么特别
递推方程
问题拆解那里其实说的比较清楚了,这里需要把之前的描述写成表达式的形式:
str1(i) == str2(j): dp[i][j] = dp[i - 1][j - 1] tip: 这里不需要考虑 dp[i - 1][j] 以及 dp[i][j - 1], 因为dp[i - 1][j - 1] <= dp[i - 1][j] +1 && dp[i - 1][j - 1] <= dp[i][j - 1] + 1 str1(i) != str2(j): dp[i][j] = Math.min(dp[i - 1][j], dp[i][j - 1], dp[i - 1][i - 1]) + 11
2
3
4
5
6
7你可以看到字符之间比较的结果永远是递推的前提
实现
这里有一个初始化,就是当一个字符串是空串的时候,转化只能通过添加元素或是删除元素来达成,那这里状态数组中存的值其实是和非空字符串的字符数量保持一致。
# 第种个解答
- 问题1:如果 word1[0..i-1] 到 word2[0..j-1] 的变换需要消耗 k 步,那 word1[0..i] 到 word2[0..j] 的变换需要几步呢?
- 答:先使用 k 步,把 word1[0..i-1] 变换到 word2[0..j-1],消耗 k 步。再把 word1[i] 改成 word2[j],就行了。如果 word1[i] == word2[j],什么也不用做,一共消耗 k 步,否则需要修改,一共消耗 k + 1 步。
- 问题2:如果 word1[0..i-1] 到 word2[0..j] 的变换需要消耗 k 步,那 word1[0..i] 到 word2[0..j] 的变换需要消耗几步呢?
- 答:先经过 k 步,把 word1[0..i-1] 变换到 word2[0..j],消耗掉 k 步,再把 word1[i] 删除,这样,word1[0..i] 就完全变成了 word2[0..j] 了。一共 k + 1 步。
- 问题3:如果 word1[0..i] 到 word2[0..j-1] 的变换需要消耗 k 步,那 word1[0..i] 到 word2[0..j] 的变换需要消耗几步呢?
- 答:先经过 k 步,把 word1[0..i] 变换成 word2[0..j-1],消耗掉 k 步,接下来,再插入一个字符 word2[j], word1[0..i] 就完全变成了 word2[0..j] 了。
从上面三个问题来看,word1[0..i] 变换成 word2[0..j] 主要有三种手段,用哪个消耗少,就用哪个。
执行用时 :16 ms, 在所有 cpp 提交中击败了72.64%的用户
内存消耗 :11.5 MB, 在所有 cpp 提交中击败了7.47%的用户
int minDistance(string word1, string word2) {
int len1 = word1.size(), len2 = word2.size();
vector<vector<int>> dp(len1+1,vector<int>(len2+1));
dp[0][0] = 0;
for (int i = 1; i <= len1; ++i) {
dp[i][0] = i;
}
for (int j = 1; j <= len2; ++j) {
dp[0][j] = j;
}
for (int i = 1; i <= len1; ++i) {
for (int j = 1; j <= len2; ++j) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min(dp[i - 1][j],
min(dp[i][j - 1], dp[i - 1][j - 1])) + 1;
}
}
}
return dp[len1][len2];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 第二版,改进一下
执行用时 :12 ms, 在所有 cpp 提交中击败了90.55%的用户
内存消耗 :11.2 MB, 在所有 cpp 提交中击败了41.63%的用户
int minDistance(string word1, string word2) {
int len1 = word1.size(), len2 = word2.size();
vector<vector<int>> dp(len1+1,vector<int>(len2+1));
for (int i = 0; i <= len1; ++i) {
for (int j = 0; j <= len2; ++j) {
if (j == 0) dp[i][0] = i; //从无到有显然要经历i步插入操作
else if (i == 0) dp[0][j] = j; //从有到无显然要经历j步删除操作
else if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min(dp[i - 1][j],
min(dp[i][j - 1], dp[i - 1][j - 1])) + 1;
}
}
}
return dp[len1][len2];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 91. 解码方法
力扣原题链接(点我直达) (opens new window)
一条包含字母 A-Z 的消息通过以下方式进行了编码:
'A' -> 1
'B' -> 2
...
'Z' -> 26
2
3
4
给定一个只包含数字的非空字符串,请计算解码方法的总数。
示例 1:
输入: "12"
输出: 2
解释: 它可以解码为 "AB"(1 2)或者 "L"(12)。
2
3
示例 2:
输入: "226"
输出: 3
解释: 它可以解码为 "BZ" (2 26), "VF" (22 6), 或者 "BBF" (2 2 6) 。
2
3
# 第一版,待改正
int numDecodings(string s) {
int len = s.size();
if (s[0] == '0') return 0; //首字母为0,肯定是不能编码的
if (len == 1) return 1;
vector<int> dp(len, 0);
dp[0] = 1;
if ((s[0] == '1' || s[0] == '2') && s[1] > '0' && s[1]<'7') dp[1] = 2;
else
dp[1] = 1;
for (int i = 2; i < len; ++i) {
if (s[i] == '0' && s[i - 1] == '0') return 0;
if (s[i] == '0') {
if (s[i - 1] == '1' || s[i - 1] == '2') dp[i] = dp[i - 2];
else
return 0;
}
else if (s[i - 1] == '1') dp[i] = dp[i - 1] + dp[i - 2];
else
if (s[i - 1] == '2' && s[i] >= '1' && s[i] <= '6') dp[i] = dp[i - 1] + dp[i - 2];
else
dp[i] = dp[i - 1];
}
return dp[len - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 第二版,看的讲解,真的很厉害啊,我好菜
执行用时 :0 ms, 在所有 cpp 提交中击败了100.00%的用户
内存消耗 :8.5 MB, 在所有 cpp 提交中击败了25.89%的用户
int numDecodings(string s) {
int len = s.size();
if (len == 0 || (len == 1 && s[0] == '0')) return 0;
if (len == 1) return 1;
vector<int> dp(len + 1, 0);
dp[0] = 1;
for (int i = 0; i < len; ++i) {
dp[i + 1] = s[i] == '0' ? 0 : dp[i];
if (i > 0 && (s[i - 1] == '1' || (s[i - 1] == '2' && s[i] <= '6'))) {
dp[i + 1] += dp[i - 1];
}
}
return dp[len];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 120. 三角形最小路径和
力扣原题链接(点我直达) (opens new window)
给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。
例如,给定三角形:
[
[2],
[3,4],
[6,5,7],
[4,1,8,3]
]~
2
3
4
5
6
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
说明:
如果你可以只使用 O(n) 的额外空间(n 为三角形的总行数)来解决这个问题,那么你的算法会很加分。
# 第一版,原地DP,速度非常快
执行用时 :4 ms, 在所有 cpp 提交中击败了97.37%的用户
内存消耗 :9.6 MB, 在所有 cpp 提交中击败了94.87%的用户
int minimumTotal(vector<vector<int>>& triangle) {
if (triangle.empty()) return 0;
if (triangle.size() == 1) return triangle[0][0];
for (int i = 1; i < triangle.size(); ++i) {
int temp = 0;
for (int j = 0; j <= i; ++j) {
if (j == 0) temp = triangle[i - 1][j];
else if (j == i) temp = triangle[i - 1][j-1];
else
temp = min(triangle[i-1][j],triangle[i-1][j - 1]);
triangle[i][j] += temp;
}
}
return *min_element(triangle.back().begin(), triangle.back().end());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
*min_element(triangle.back().begin(), triangle.back().end());这是求最小值的一个算法
# 第二版,第二种原地DP,更快一点了
执行用时 :4 ms, 在所有 cpp 提交中击败了97.37%的用户
内存消耗 :9.6 MB, 在所有 cpp 提交中击败了94.21%的用户
int minimumTotal(vector<vector<int>>& triangle) {
for (int i = triangle.size() - 2; i >= 0; i--)
for (int j = 0; j < triangle[i].size(); j++)
triangle[i][j] += min(triangle[i + 1][j], triangle[i + 1][j + 1]);
return triangle[0][0];
}
2
3
4
5
6
# 第三版-改进版
int n = triangle.size();
vector<int> dp(n,0);
for (int i = 0; i < n; i++)
dp[i] = triangle[n - 1][i];
for (int i = n - 2; i >= 0; i--) {
for (int j = 0; j <= i; j++) {
dp[j] = min(dp[j], dp[j + 1]) + triangle[i][j];
}
}
return dp[0];
2
3
4
5
6
7
8
9
10
11
12
# 139. 单词拆分
力扣原题链接(点我直达) (opens new window)
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
- 拆分时可以重复使用字典中的单词。
- 你可以假设字典中没有重复的单词。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
2
3
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。
注意你可以重复使用字典中的单词。
2
3
4
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
2
# 1、经典的DP问题与解法
执行用时:28 ms, 在所有 C++ 提交中击败了58.27%的用户
内存消耗:13.1 MB, 在所有 C++ 提交中击败了48.48%的用户
bool wordBreak(string s, vector<string>& wordDict) {
int len = s.size();
vector<bool> dp(len+1,false);
unordered_set<string> unset(wordDict.begin(), wordDict.end());
dp[0] = true;
for( int i = 1 ; i <= len; ++i ){
for( int j = 0; j < i; ++j ){
if( dp[j] == true && unset.find(s.substr( j, i-j )) != unset.end())
{
dp[i] = true;
break;
}
}
}
return dp[len];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 2、适当优化
对于以上代码可以优化。每次并不需要从s[0]开始搜索。因为wordDict中的字符串长度是有限的。只需要从i-maxWordLength开始搜索就可以了。
执行用时:0 ms, 在所有 C++ 提交中击败了100.00%的用户
内存消耗:7.7 MB, 在所有 C++ 提交中击败了100.00%的用户
bool wordBreak(string s, vector<string>& wordDict) {
int len = s.size();
vector<bool> dp(len + 1, false);
unordered_set<string> unset(wordDict.begin(), wordDict.end());
dp[0] = true;
int maxLen=0;
for (int i = 0; i < wordDict.size(); ++i) {
maxLen = max(maxLen, (int)wordDict[i].size());
}
for (int i = 1; i <= len; ++i) {//这里是从1开始的,因为dp[0]无意义
for (int j = max(0,i - maxLen); j < i; ++j) {//这里要有个max的判断,可能在s中还没到最长的长度
if (dp[j] == true && unset.find(s.substr(j, i - j)) != unset.end())
{
dp[i] = true;
break;
}
}
}
return dp[len];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 140. 单词拆分 II
力扣原题链接(点我直达) (opens new window)
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
说明:
- 分隔时可以重复使用字典中的单词。
- 你可以假设字典中没有重复的单词。
示例 1:
输入:
s = "catsanddog"
wordDict = ["cat", "cats", "and", "sand", "dog"]
输出:
[
"cats and dog",
"cat sand dog"
]
2
3
4
5
6
7
8
示例 2:
输入:
s = "pineapplepenapple"
wordDict = ["apple", "pen", "applepen", "pine", "pineapple"]
输出:
[
"pine apple pen apple",
"pineapple pen apple",
"pine applepen apple"
]
解释: 注意你可以重复使用字典中的单词。
2
3
4
5
6
7
8
9
10
示例 3:
输入:
s = "catsandog"
wordDict = ["cats", "dog", "sand", "and", "cat"]
输出:
[]
2
3
4
5
# 1、这是真的不会,看了答案也不会
//回溯+剪枝,利用一个map保留键值映射,想相当于加入剪枝操作,可以对之前计算过的避免重复计算,进而加速计算过程。
vector<string> wordBreakCore(unordered_map<string, vector<string> >& m, vector<string>& wordDict, string s) {
if (m.count(s)>0) return m[s];
if (s.empty()) return { "" };
vector<string> res;
for (auto &word : wordDict) {
if (s.substr(0, word.size()) != word) continue;
vector<string> tmp = wordBreakCore(m, wordDict, s.substr(word.size()));
for (auto& itm : tmp) {
res.push_back(word + (itm.empty() ? "" : " " + itm));
}
}
m[s] = res;
return res;
}
vector<string> wordBreak(string s, vector<string>& wordDict) {
unordered_map<string, vector<string> > m;
return wordBreakCore(m, wordDict, s);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 152. 乘积最大子序列 同样经典的问题
力扣原题链接(点我直达) (opens new window)
给定一个整数数组 nums ,找出一个序列中乘积最大的连续子序列(该序列至少包含一个数)。
示例 1:
输入: [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。
2
3
示例 2:
输入: [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
2
3
https://leetcode-cn.com/problems/maximum-product-subarray/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by--36/
# 解法一 分段法
给乘积带来问题的是0和负数。
1,用0将序列分割成不再包含0的段。每个段中的最大值,再与0比较取最大值。
例如:[2,3,0,4]
分成两段。[2,3],[4]。段内最大值为6,4。与0比较。整个序列的最大值为6
例如:[2,-3,0,-4]
分成两段。[2,-3],[-4]。段内最大值为2,-4。与0比较。整个序列的最大值为2
2,负数的个数很关键。如果有偶数个负数,负数相乘为正数,那么全部乘积应该是最大的。
如果有奇数个负数,那么用第一个奇数A将序列分成两段。两段中的最大值,再与A比较取最大值。
另外, 用最后一个奇数B将序列分成两段。两段中的最大值,再与B比较取最大值。
例如:[2,3,-2,4] -2将序列分成两段。[2,3]和[4]。两段的最大值为6和4.
例如:[3,-2,-3,-3,1,3,0]
-2将序列分成两段。 [3]和[ -3,-3,1,3,0 ]。最大值为3和27.最大值为27.
最后一个-3,将序列分成两段。 [3,-2,-3 ]和[ 1,3,0 ]。最大值为18和3. 最大值为18.
最终最大值为27.
关键是用方便的方法指出第一个和最后一个负数。
从左向右累乘,当到最后一个负数时,左边的偶数个负数都乘过了。乘上此负数,值就变成负数了。最大值显然是左边的最大值。
从右向左累乘,当到最后一个负数时,右边的偶数个负数都乘过了。乘上此负数,值就变成负数了。最大值显然是右边的最大值。
执行用时 :8 ms, 在所有 cpp 提交中击败了64.69%的用户
内存消耗 :9.1 MB, 在所有 cpp 提交中击败了32.52%的用户
int maxProduct(vector<int>& nums) {
int res = nums[0];
int left_max = 1;
for (auto &a:nums) {
left_max *= a;
if(left_max>res) res = left_max;
if(left_max == 0) left_max=1;
}
int right_max = 1;
for (int i = nums.size() - 1; i >= 0; --i) {
right_max *= nums[i];
if (right_max > res) res = right_max;
if (right_max == 0) right_max = 1;
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 第二版,动态规划DP
解法二 动态规划 设d[i]表示以A[i]为结尾的乘积最大值。
设e[i]表示以A[i]为结尾的乘积最小值。
当A[i] >=0 且 d[i-1]>=0时,d[i]=A[i]*d[i-1]。
当A[i] >=0 且 d[i-1] < 0时,d[i]=A[i]。
当A[i] <0 且 e[i-1] <0 时,d[i]=A[i] * e[i-1]。
当 A[i]<0 且 e[i-1] >= 0 时,d[i]=A[i] 。
d[i]=max( A[i]*d[i-1] , A[i] , A[i] * e[i-1] )。
用同样的方法求e.
当A[i] >=0 且 e[i-1]>=0时,e[i]=A[i]。
当A[i] >=0 且 e[i-1] < 0时,e[i]=A[i]*e[i-1]。
当A[i] <0 且 d[i-1] <0 时,e[i]=A[i]。
当 A[i]<0 且 d[i-1] >= 0 时,e[i]=A[i]*d[i-1] 。
e[i]=max( A[i]*d[i-1] , A[i] , A[i] * e[i-1] )。
执行用时 :8 ms, 在所有 cpp 提交中击败了64.69%的用户
内存消耗 :9.2 MB, 在所有 cpp 提交中击败了22.62%的用户
int maxProduct(vector<int>& nums) {
int N = nums.size();
vector<int> d(N), e(N);
d[0] = nums[0];
e[0] = nums[0];
int ans = INT_MIN;
ans = max(ans, max(d[0], e[0]));
for (int i = 1; i < N; ++i) {
d[i] = max(nums[i], max(nums[i] * d[i - 1], nums[i] * e[i - 1]));
e[i] = min(nums[i], min(nums[i] * d[i - 1], nums[i] * e[i - 1]));
ans = max(ans, max(d[i], e[i]));
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 精简版
执行用时 :4 ms, 在所有 cpp 提交中击败了93.25%的用户
内存消耗 :8.9 MB, 在所有 cpp 提交中击败了89.24%的用户
int maxProduct(vector<int>& nums) {
int n = nums.size();
if (n == 0) {
return 0;
}
int dpMax = nums[0];
int dpMin = nums[0];
int maxNum = nums[0];
for (int i = 1; i < n; i++) {
//更新 dpMin 的时候需要 dpMax 之前的信息,所以先保存起来
int preMax = dpMax;
dpMax = max(dpMin * nums[i], max(dpMax * nums[i], nums[i]));
dpMin = min(dpMin * nums[i], min(preMax * nums[i], nums[i]));
maxNum = max(maxNum, dpMax);
}
return maxNum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 221. 最大正方形
力扣原题链接(点我直达) (opens new window)
在一个由 0 和 1 组成的二维矩阵内,找到只包含 1 的最大正方形,并返回其面积。
示例:
输入:
1 0 1 0 0
1 0 1 1 1
1 1 1 1 1
1 0 0 1 0
输出: 4
2
3
4
5
6
7
8
# 第一版,改了又改
执行用时 :20 ms, 在所有 cpp 提交中击败了79.27%的用户
内存消耗 :11.1 MB, 在所有 cpp 提交中击败了62.99%的用户
int maximalSquare(vector<vector<char>>& matrix) {
if (matrix.empty() || matrix[0].empty()) return 0;
int m = matrix.size(), n = matrix[0].size();
int length = 0;
vector<vector<int>> res(m, vector<int>(n, 0));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if(matrix[i][j]== '1'){
if (i == 0 || j == 0)
res[i][j] = 1;
else
res[i][j] = min(min(res[i - 1][j - 1], res[i - 1][j]), res[i][j - 1])+1;
length = max(length, res[i][j]);
}
}
}
return pow(length,2);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 263. 丑数
力扣原题链接(点我直达) (opens new window)
编写一个程序判断给定的数是否为丑数。
丑数就是只包含质因数 2, 3, 5 的正整数。
示例 1:
输入: 6
输出: true
解释: 6 = 2 × 3
2
3
示例 2:
输入: 8
输出: true
解释: 8 = 2 × 2 × 2
2
3
示例 3:
输入: 14
输出: false
解释: 14 不是丑数,因为它包含了另外一个质因数 7。
2
3
说明:
1是丑数。- 输入不会超过 32 位有符号整数的范围: [−231, 231 − 1]。
# 第一版,自己写的,还可以吧,比较复杂来着
执行用时 :4 ms, 在所有 cpp 提交中击败了73.94%的用户
内存消耗 :8.1 MB, 在所有 cpp 提交中击败了23.30%的用户
bool isUgly(int num) {
if (num <= 0) return false;
if (num == 1) return true;
if (num % 2 == 0) {
while (num % 2 == 0) {
num = num / 2;
}
if (num == 1) return true;
if (num % 3 == 0) {
while (num % 3 == 0) {
num = num / 3;
}
if (num == 1) return true;
if (num % 5 == 0) {
while (num % 5 == 0) {
num = num / 5;
}
if (num == 1) return true;
else return false;
}
}
else if (num % 5 == 0) {
while (num % 5 == 0) {
num = num / 5;
}
if (num == 1) return true;
else return false;
}
} // 不包含2
else if (num % 3 == 0) {
while (num % 3 == 0) {
num = num / 3;
}
if (num == 1) return true;
if (num % 5 == 0) {
while (num % 5 == 0) {
num = num / 5;
}
if (num == 1) return true;
else return false;
}
}//不包含3
else if (num % 5 == 0) {
while (num % 5 == 0) {
num = num / 5;
}
if (num == 1) return true;
else return false;
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 第二版,其实我想复杂了,很容易的
执行用时 :4 ms, 在所有 cpp 提交中击败了73.94%的用户
内存消耗 :8.2 MB, 在所有 cpp 提交中击败了5.93%的用户
bool isUgly(int num) {
if (num <= 0) {
return false;
}
while (num % 2 == 0) num >>= 1; //位运算代替除法,要快一点
while (num % 3 == 0) num /= 3;
while (num % 5 == 0) num /= 5;
return num == 1;
}
2
3
4
5
6
7
8
9
10
# 第三版,最快的一种方法
执行用时 :0 ms, 在所有 cpp 提交中击败了100.00%的用户
内存消耗 :8 MB, 在所有 cpp 提交中击败了39.78%的用户
bool isUgly(int num) {
if (num <= 0) {
return false;
}
while (num != 1) {
if (num % 2 == 0) num >>= 1; //位运算要快于除法
else if (num % 3 == 0) num /= 3;
else if (num % 5 == 0) num /= 5;
else return false; //如果一趟下来num的值没变,则num无法被2,3,5整除
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
# 264. 丑数 II
力扣原题链接(点我直达) (opens new window)
编写一个程序,找出第 n 个丑数。
丑数就是只包含质因数 2, 3, 5 的正整数。
示例:
输入: n = 10
输出: 12
解释: 1, 2, 3, 4, 5, 6, 8, 9, 10, 12 是前 10 个丑数。
2
3
说明:
1是丑数。n不超过1690。
# 第一版,暴力法,超时,方法是对的
int nthUglyNumber(int n) {
if (n == 1) return 1;
int index = 2,temp=2;
while (index) {
temp = index;
while (temp != 1) {
if (temp % 2 == 0) temp >>= 1;
else if (temp % 3 == 0) temp /= 3;
else if (temp % 5 == 0) temp /= 5;
else break;
}
if (temp == 1) n--;
if (n == 1)
{
break;
}
else
index++;
}
return index;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 第二版,看的思路,三指针法,真的天才
1-6肯定都是丑数,所以当丑数数量小于7个时直接返回数量
执行用时 :8 ms, 在所有 cpp 提交中击败了89.97%的用户
内存消耗 :9.7 MB, 在所有 cpp 提交中击败了71.64%的用户
int nthUglyNumber(int n) {
if (n < 1) return n;
vector<int> dp(n, 0);
dp[0] = 1;
int indexTwo = 0, indexThree = 0, indexFive = 0;
for (int i = 1; i < n; ++i) {
int minNum = min(min(dp[indexTwo] * 2, dp[indexThree] * 3), dp[indexFive] * 5);
if (minNum == dp[indexTwo] * 2) indexTwo++;
if (minNum == dp[indexThree] * 3) indexThree++;
if (minNum == dp[indexFive] * 5) indexFive++;
dp[i] = minNum;
}
return dp[n-1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 300. 最长上升子序列
力扣原题链接(点我直达) (opens new window)
给定一个无序的整数数组,找到其中最长上升子序列的长度。
示例:
输入: [10,9,2,5,3,7,101,18] 输出: 4 解释: 最长的上升子序列是 [2,3,7,101],它的长度是 4。 说明:
可能会有多种最长上升子序列的组合,你只需要输出对应的长度即可。 你算法的时间复杂度应该为 O(n2) 。 进阶: 你能将算法的时间复杂度降低到 O(n log n) 吗?
# 第一版,看了提示写的,还可以
执行用时 :36 ms, 在所有 cpp 提交中击败了71.49%的用户
内存消耗 :8.6 MB, 在所有 cpp 提交中击败了60.41%的用户
int lengthOfLIS(vector<int>& nums) {
if (nums.empty()) return 0;
stack<int> stk;
vector<int> res(nums.size(), 0);
res[0] = 1;
int len = 0;
for (unsigned i = 1; i < nums.size(); ++i) {
len = 0;
for (unsigned j = 0; j < i; ++j) {
if (nums[j] < nums[i]) {
len = max(res[j], len);
}
}
res[i] = len + 1;
}
return *max_element(res.begin(),res.end());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
第二种写法
if (nums.empty()) return 0;
vector<int> res(nums.size(), 1);
int maxNum = 0;
for (int i = 0; i < nums.size(); ++i) {
for (int j = 0; j < i; ++j) {
if (nums[i] > nums[j]) {
res[i] = max(res[j] + 1, res[i]);
}
}
maxNum = max(maxNum, res[i]);
}
return maxNum;
2
3
4
5
6
7
8
9
10
11
12
13
14
# 第二版,DP+二分
执行用时 :4 ms, 在所有 cpp 提交中击败了96.36%的用户
内存消耗 :8.5 MB, 在所有 cpp 提交中击败了83.66%的用户
int lengthOfLIS(vector<int>& nums) {
if (nums.empty()) return{};
vector<int> tail(nums.size(), 0);
tail[0] = nums[0];
int end = 0;
for (int i = 1; i < nums.size(); i++) {
if (nums[i] > tail[end]) tail[++end] = nums[i];
else {
int l = 0, r = end, mid;
while (l <= r) {
mid = (l + r) >> 1;
if (tail[mid] > nums[i] && (mid == 0 || (mid > 0 && tail[mid - 1] < nums[i]))) tail[mid] = nums[i];
else if (tail[mid] <= nums[i]) l = mid + 1;
else r = mid - 1;
}
}
}
return end + 1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 322. 零钱兑换
力扣原题链接(点我直达) (opens new window)
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
示例 1:
输入: coins = [1, 2, 5], amount = 11
输出: 3
解释: 11 = 5 + 5 + 1
2
3
示例 2:
输入: coins = [2], amount = 3
输出: -1
2
说明: 你可以认为每种硬币的数量是无限的。
# 1、经典DP,好好想想
执行用时:148 ms, 在所有 C++ 提交中击败了39.78%的用户
内存消耗:14 MB, 在所有 C++ 提交中击败了59.87%的用户
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, amount + 1);
dp[0] = 0;
for(int i = 0; i <= amount; ++i){
for(auto coin:coins){
if(i < coin) continue;
dp[i] = min(dp[i], 1 + dp[i - coin]);
}
}
return dp[amount] == amount+1?-1:dp[amount];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2、稍微优化一下
执行用时:140 ms, 在所有 C++ 提交中击败了48.87%的用户
内存消耗:14.4 MB, 在所有 C++ 提交中击败了15.72%的用户
int coinChange(vector<int>& coins, int amount) {
vector<int> dp(amount + 1, amount + 1);
dp[0] = 0;
sort(coins.begin(), coins.end());
for(int i = 0; i <= amount; ++i){
for(auto coin:coins){
if(i < coin) break;
dp[i] = min(dp[i], 1 + dp[i - coin]);
}
}
return dp[amount] == amount+1?-1:dp[amount];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 413. 等差数列划分
力扣原题链接(点我直达) (opens new window)
如果一个数列至少有三个元素,并且任意两个相邻元素之差相同,则称该数列为等差数列。
例如,以下数列为等差数列:
1, 3, 5, 7, 9
7, 7, 7, 7
3, -1, -5, -9
2
3
以下数列不是等差数列。
1, 1, 2, 5, 7
数组 A 包含 N 个数,且索引从0开始。数组 A 的一个子数组划分为数组 (P, Q),P 与 Q 是整数且满足 0<=P<Q<N 。
如果满足以下条件,则称子数组(P, Q)为等差数组:
元素 A[P], A[p + 1], ..., A[Q - 1], A[Q] 是等差的。并且 P + 1 < Q 。
函数要返回数组 A 中所有为等差数组的子数组个数。
示例:
A = [1, 2, 3, 4]
返回: 3, A 中有三个子等差数组: [1, 2, 3], [2, 3, 4] 以及自身 [1, 2, 3, 4]。
2
3
# 第一版,自己写的,错误
int numberOfArithmeticSlices(vector<int>& A) {
if (A.size() <= 2) return 0;
int len = A.size(),sum=0;
vector<int> dp(len, 0);
if (A[0] + A[2] == 2 * A[1]) dp[2] = 3;
//sum += dp[2];
for (int i = 3; i < len; ++i) {
if (2 * A[i - 1] == A[i] + A[i - 2]) dp[i] = dp[i - 1]==0?3:dp[i-1]+1;
}
//for (auto a : dp) {
// cout << a << " ";
//}
//cout << endl;
for (int i = 2; i < len; ++i) {
if (dp[i] == 0) continue;
if (dp[i] == 3) {
while (i < len && dp[i] >= 3) {
i++;
}
//cout << "i " << i << endl;
if (dp[i - 1] > 3) sum += (dp[i - 1] - 2) * (dp[i - 1] - 1) / 2;
else if (i < len && dp[i] == 3) sum += 1;
else if (i == len && dp[i - 1] == 3) sum += 1;
}
}
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 第二版,想错了鸭,改过来了
执行用时 :8 ms, 在所有 cpp 提交中击败了30.09%的用户
内存消耗 :8.8 MB, 在所有 cpp 提交中击败了33.33%的用户
int numberOfArithmeticSlices(vector<int>& A) {
if (A.size() <= 2) return 0;
int len = A.size(), sum = 0;
vector<int> dp(len, 0);//dp[i]用于保存以A[i]结尾的等差数列的个数
for (int i = 2; i < len; ++i) {//等差数列长度需要大于2,所以前两个必定为0
//判断步长
if (A[i] + A[i - 2] == 2*A[i - 1]) {
dp[i] = dp[i - 1] + 1;//转移方程
sum += dp[i];//求和
}
}
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 第三版,改进版
执行用时 :0 ms, 在所有 cpp 提交中击败了100.00%的用户
内存消耗 :8.6 MB, 在所有 cpp 提交中击败了92.06%的用户
int numberOfArithmeticSlices(vector<int>& A) {
if (A.size() <= 2) return 0;
int len = A.size(), sum = 0, count=0;
for (int i = 2; i < len; ++i) {
if (A[i] + A[i - 2] == 2 * A[i - 1]) {
count += 1;
sum += count;
}
else
count = 0;
}
return sum;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 516. 最长回文子序列 依然经典
力扣原题链接(点我直达) (opens new window)
给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。
示例 1: 输入:
"bbbab"
输出:
4
一个可能的最长回文子序列为 "bbbb"。
示例 2: 输入:
"cbbd"
输出:
2
一个可能的最长回文子序列为 "bb"。
# 第一版,标准DP做法
执行用时 :140 ms, 在所有 cpp 提交中击败了31.14%的用户
内存消耗 :69.5 MB, 在所有 cpp 提交中击败了48.19%的用户
int longestPalindromeSubseq(string s) {
if (s.size() <= 1) return s.size();
int n = s.size();
vector<vector<int>> dp(n, vector<int>(n, 1));
for (int i = n - 1; i >= 0; --i) {
for (int j = i; j < n; ++j) {
if (s[i] == s[j] && j - i <= 1) { //如果相等且相邻或者i==j
dp[i][j] = j - i + 1;
}
else if (s[i] == s[j]) { //如果相等但是不相邻
dp[i][j] = dp[i + 1][j - 1] + 2;
}
else if(s[i] != s[j]) //如果不相等
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
//cout << i << " " << j << " " << dp[i][j] << endl;
}
}
return dp[0][n-1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 第二版,稍微改进一下DP
执行用时 :88 ms, 在所有 cpp 提交中击败了71.80%的用户
内存消耗 :69.4 MB, 在所有 cpp 提交中击败了50.00%的用户
int longestPalindromeSubseq(string s) {
if (s.size() <= 1) return s.size();
int n = s.size();
vector<vector<int>> dp(n, vector<int>(n, 1));
for (int i = n - 1; i >= 0; --i) {
for (int j = i+1; j < n; ++j) {//直接从下一个开始,不再从i开始了
if (s[i] == s[j] && j - i == 1) { //如果相等且相邻或者i==j
dp[i][j] = 2;
}
else if (s[i] == s[j]) { //如果相等但是不相邻
dp[i][j] = dp[i + 1][j - 1] + 2;
}
else if (s[i] != s[j]) //如果不相等
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
//cout << i << " " << j << " " << dp[i][j] << endl;
}
}
return dp[0][n - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 字符匹配类动态规划题目
它的题目特征其实特别明显,比如:
- 输入是两个字符串,问是否通过一定的规则相匹配
- 输入是两个字符串,问两个字符串是否存在包含被包含的关系
- 输入是两个字符串,问一个字符串怎样通过一定规则转换成另一个字符串
- 输入是两个字符串,问它们的共有部分
这类问题的难点在于问题的拆解上面,也就是如何找到当前问题和子问题的联系。
往往这类问题的状态比较好找,你可以先假设状态 **dp[i][j] 就是子问题str1(0...i) str2(0...j) 的状态。拆解问题主要思考 dp[i][j] 和子问题的状态dp[i - 1][j],dp[i - 1][j] 以及 dp[i - 1][j - 1] 的联系,**因为字符串会存在空串的情况,所以动态规划状态数组往往会多开一格。
当然,对于这类问题,如果你还是没有什么思路或者想法,我给你的建议是 画表格,我们结合实际题目一起来看看。
# 518. 零钱兑换 II
力扣原题链接(点我直达) (opens new window)
给定不同面额的硬币和一个总金额。写出函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
示例 1:
输入: amount = 5, coins = [1, 2, 5]
输出: 4
解释: 有四种方式可以凑成总金额:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
2
3
4
5
6
7
示例 2:
输入: amount = 3, coins = [2]
输出: 0
解释: 只用面额2的硬币不能凑成总金额3。
2
3
示例 3:
输入: amount = 10, coins = [10]
输出: 1
2
注意
你可以假设:
- 0 <= amount (总金额) <= 5000
- 1 <= coin (硬币面额) <= 5000
- 硬币种类不超过 500 种
- 结果符合 32 位符号整数
# 1、看的答案,大概明白点了
int change(int amount, vector<int>& coins) {
int len = coins.size();
vector<int> res(amount+1,0);
res[0] = 1;
for(auto coin:coins){
for(int j = coin;j<=amount; ++ j){
res[j] += res[j-coin];
}
}
return res[amount];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 2、自己写的和总结的,万字精髓所在啊
执行用时:40 ms, 在所有 C++ 提交中击败了34.43%的用户
内存消耗:18.5 MB, 在所有 C++ 提交中击败了19.57%的用户
int change(int amount, vector<int>& coins) {
int len = coins.size();
vector<vector<int>> dp(len + 1, vector<int>(amount + 1, 0));// dp[i][j] 只有 i 种货币,而金额有 j的时候,可以兑换的组合数
for (int i = 0; i <= len; ++i) {//当金额只有 0 的时候,什么组合也没有,所以就是啥都不选的情况下,啥都不选也就是那唯一的一次选择
dp[i][0] = 1;
}
//for (int i = 0; i <= amount; ++i) {//当没有硬币的时候,不管钱有多少
// dp[0][i] = 0;
//}//这一步最好不要,因为当输入amount = 0,coins = [] 的时候,本来应该是输出为1的,也就是上面那种结果,现在又赋值一次,把1覆盖掉,变成0了
for (int i = 1; i <= len; ++i) {
int coin = coins[i - 1];//此时的硬币数
for (int j = 1; j <= amount; ++j) {
if (coin > j) {//此时的硬币面额大于拥有的金额数,比如我又1块的隐蔽,但是你只有1毛钱,这就没办法组合
dp[i][j] = dp[i - 1][j];
}
else {//此时硬币面额小于拥有的钱数,此时的可能性有多少种呢,
//1,上一个j金额时的可能性,也就是d[i-1][j]的时候,2、上一个钱不太够的时候也就是dp[i][j-coin]
// 那么加起来就是dp[i][j]的全部可能性了
dp[i][j] = dp[i-1][j] + dp[i][j - coin];
}
}
}
return dp[len][amount];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 583. 两个字符串的删除操作
力扣原题链接(点我直达) (opens new window)
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
示例 1:
输入: "sea", "eat"
输出: 2
解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea"
2
3
说明:
- 给定单词的长度不超过500。
- 给定单词中的字符只含有小写字母。
# 第一版,经典DP做法
执行用时 :24 ms, 在所有 cpp 提交中击败了65.38%的用户
内存消耗 :14.2 MB, 在所有 cpp 提交中击败了76.74%的用户
int minDistance(string word1, string word2) {
if (word1.empty()) return word2.size();
else if (word2.empty()) return word1.size();
int len1 = word1.size(), len2 = word2.size();
vector<vector<int>> dp(len1, vector<int>(len2, 0));
if (word1[0] == word2[0]) dp[0][0] = 1;
for (int i = 1; i < len1; ++i) {
if (word1[i] == word2[0]) dp[i][0] = 1;
else
dp[i][0] = dp[i - 1][0];
}
for (int j = 1; j < len2; ++j) {
if (word2[j] == word1[0]) dp[0][j] = 1;
else
dp[0][j] = dp[0][j-1];
}
for (int i = 1; i < len1; ++i) {
for (int j = 1; j < len2; ++j) {
if (word1[i] == word2[j]) dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
return len1 + len2 - 2 * dp[len1-1][len2-1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 638. 大礼包 未做
力扣原题链接(点我直达)
在LeetCode商店中, 有许多在售的物品。
然而,也有一些大礼包,每个大礼包以优惠的价格捆绑销售一组物品。
现给定每个物品的价格,每个大礼包包含物品的清单,以及待购物品清单。请输出确切完成待购清单的最低花费。
每个大礼包的由一个数组中的一组数据描述,最后一个数字代表大礼包的价格,其他数字分别表示内含的其他种类物品的数量。
任意大礼包可无限次购买。
示例 1:
输入: [2,5], [[3,0,5],[1,2,10]], [3,2]
输出: 14
解释:
有A和B两种物品,价格分别为¥2和¥5。
大礼包1,你可以以¥5的价格购买3A和0B。
大礼包2, 你可以以¥10的价格购买1A和2B。
你需要购买3个A和2个B, 所以你付了¥10购买了1A和2B(大礼包2),以及¥4购买2A。
2
3
4
5
6
7
示例 2:
输入: [2,3,4], [[1,1,0,4],[2,2,1,9]], [1,2,1]
输出: 11
解释:
A,B,C的价格分别为¥2,¥3,¥4.
你可以用¥4购买1A和1B,也可以用¥9购买2A,2B和1C。
你需要买1A,2B和1C,所以你付了¥4买了1A和1B(大礼包1),以及¥3购买1B, ¥4购买1C。
你不可以购买超出待购清单的物品,尽管购买大礼包2更加便宜。
2
3
4
5
6
7
说明:
- 最多6种物品, 100种大礼包。
- 每种物品,你最多只需要购买6个。
- 你不可以购买超出待购清单的物品,即使更便宜。
# 647. 回文子串
力扣原题链接(点我直达) (opens new window)
给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被计为是不同的子串。
示例 1:
输入: "abc"
输出: 3
解释: 三个回文子串: "a", "b", "c".
2
3
示例 2:
输入: "aaa"
输出: 6
说明: 6个回文子串: "a", "a", "a", "aa", "aa", "aaa".
2
3
注意:
- 输入的字符串长度不会超过1000。
# 第一版,自己写的,效果超级差
执行用时 :296 ms, 在所有 cpp 提交中击败了12.80%的用户
内存消耗 :13.3 MB, 在所有 cpp 提交中击败了42.54%的用户
bool Substrings(string& temp) {
int i = 0, j = temp.size()-1;
while (i < j) {
if (temp[i] == temp[j]) {
++i;
--j;
}
else
return false;
}
return true;
}
int countSubstrings(string s) {
if (s.size() <= 1) return s.size();
int len = s.size(),count=1;
for (int i = 1; i < len; ++i) {//第一个元素肯定是1个,从第二个开始判断
count += 1;
string temp = "";
temp += s[i];
for (int j = i-1; j>=0; --j) {
temp+=s[j];
if (Substrings(temp)) count += 1;
}
}
return count;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 第二版,经典DP解法
执行用时 :28 ms, 在所有 cpp 提交中击败了36.93%的用户
内存消耗 :9.9 MB, 在所有 cpp 提交中击败了58.33%的用户
int countSubstrings(string s) {
if (s.size() <= 1) return s.size();
int res = 0,n = s.length();
// dp[i][j] 表示[i,j]的字符是否为回文子串
vector<vector<bool>> dp (n+1,vector<bool>(n+1,false));
// 注意,外层循环要倒着写,内层循环要正着写
// 因为要求dp[i][j] 需要知道dp[i+1][j-1]
for (int i = n - 1; i >= 0; i--) {
for (int j = i; j < n; j++) {
// 当两个字符s[i]和s[j]相邻或者干脆i=j时,一定是回文串或者当s[i] 和s[j]不相邻时,此时只需要判断dp[i+1][j-1]和是s[i],s[j]是否相等即可得出结论
if (s[i] == s[j] && (j - i ==1 || dp[i + 1][j - 1])) {
dp[i][j] = true;
res++;
}
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 第三种,中心向外扩散的方法,经典
执行用时 :8 ms, 在所有 cpp 提交中击败了86.25%的用户
内存消耗 :8.5 MB, 在所有 cpp 提交中击败了93.42%的用户
int Substrings(string &s,int i,int j) {
int cut=0;
while ( i>=0 && j<s.size() && s[i]==s[j]) {
--i;
++j;
++cut;
}
return cut;
}
int countSubstrings(string s) {
if (s.size() <= 1) return s.size();
int len = s.size(),cut=0;
for(int i = 0; i < len; ++i){
cut += Substrings(s, i, i);//回文子串可能以一个为中心,比如aba这样的,那就从b开始
cut += Substrings(s, i, i+1); //回文子串可能以两个为中心,比如abba这样的,从bb开始走
}
return cut;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 712. 两个字符串的最小ASCII删除和
力扣原题链接(点我直达) (opens new window)
给定两个字符串s1, s2,找到使两个字符串相等所需删除字符的ASCII值的最小和。
示例 1:
输入: s1 = "sea", s2 = "eat" 输出: 231 解释: 在 "sea" 中删除 "s" 并将 "s" 的值(115)加入总和。 在 "eat" 中删除 "t" 并将 116 加入总和。 结束时,两个字符串相等,115 + 116 = 231 就是符合条件的最小和。 示例 2:
输入: s1 = "delete", s2 = "leet" 输出: 403 解释: 在 "delete" 中删除 "dee" 字符串变成 "let", 将 100[d]+101[e]+101[e] 加入总和。在 "leet" 中删除 "e" 将 101[e] 加入总和。 结束时,两个字符串都等于 "let",结果即为 100+101+101+101 = 403 。 如果改为将两个字符串转换为 "lee" 或 "eet",我们会得到 433 或 417 的结果,比答案更大。 注意:
0 < s1.length, s2.length <= 1000。 所有字符串中的字符ASCII值在[97, 122]之间。
# 第一版,做了好久,糊涂了
执行用时 :36 ms, 在所有 cpp 提交中击败了69.16%的用户
内存消耗 :17.5 MB, 在所有 cpp 提交中击败了53.73%的用户
int minimumDeleteSum(string s1, string s2) {
int len1 = s1.size(), len2 = s2.size();
vector<vector<int>> dp(len1, vector<int>(len2, 0));
if (s1[0] == s2[0]) dp[0][0] = s1[0];
for (int i = 1; i < len1; ++i) {
if (s1[i] == s2[0]) dp[i][0] = s1[i];
else
dp[i][0] = dp[i-1][0];
}
for (int j = 1; j < len2; ++j) {
if (s2[j] == s1[0]) dp[0][j] = s2[j];
else
dp[0][j] = dp[0][j-1];
}
for (int i = 1; i < len1; ++i) {
for (int j = 1; j < len2; ++j) {
if (s1[i] == s2[j])
{
dp[i][j] = dp[i - 1][j - 1] + s1[i];
}
else
{
dp[i][j] = max(dp[i-1][j],dp[i][j-1]);
}
}
}
int sum = 0;
for (auto& s : s1)
sum += s;
for (auto& s : s2)
sum += s;
return sum - 2 * dp[len1 - 1][len2 - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 第二版,提了一点时间
执行用时 :32 ms, 在所有 cpp 提交中击败了82.79%的用户
内存消耗 :17.4 MB, 在所有 cpp 提交中击败了58.21%的用户
int minimumDeleteSum(string s1, string s2) {
int len1 = s1.size(), len2 = s2.size();
vector<vector<int>> dp(len1, vector<int>(len2, 0));
if (s1[0] == s2[0]) dp[0][0] = s1[0];
for (int i = 1; i < len1; ++i) {
if (s1[i] == s2[0]) dp[i][0] = s1[i];
else
dp[i][0] = dp[i - 1][0];
}
for (int j = 1; j < len2; ++j) {
if (s2[j] == s1[0]) dp[0][j] = s2[j];
else
dp[0][j] = dp[0][j - 1];
}
int sum = s1[0];
for (int i = 1; i < len1; ++i) {
sum += s1[i];
for (int j = 1; j < len2; ++j) {
if (s1[i] == s2[j])
{
dp[i][j] = dp[i - 1][j - 1] + s1[i];
}
else
{
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
for (auto& s : s2)
sum += s;
return sum - 2 * dp[len1 - 1][len2 - 1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 877. 石子游戏
力扣原题链接(点我直达) (opens new window)
亚历克斯和李用几堆石子在做游戏。偶数堆石子排成一行,每堆都有正整数颗石子 piles[i] 。
游戏以谁手中的石子最多来决出胜负。石子的总数是奇数,所以没有平局。
亚历克斯和李轮流进行,亚历克斯先开始。 每回合,玩家从行的开始或结束处取走整堆石头。 这种情况一直持续到没有更多的石子堆为止,此时手中石子最多的玩家获胜。
假设亚历克斯和李都发挥出最佳水平,当亚历克斯赢得比赛时返回 true ,当李赢得比赛时返回 false 。
示例:
输入:[5,3,4,5]
输出:true
解释:
亚历克斯先开始,只能拿前 5 颗或后 5 颗石子 。
假设他取了前 5 颗,这一行就变成了 [3,4,5] 。
如果李拿走前 3 颗,那么剩下的是 [4,5],亚历克斯拿走后 5 颗赢得 10 分。
如果李拿走后 5 颗,那么剩下的是 [3,4],亚历克斯拿走后 4 颗赢得 9 分。
这表明,取前 5 颗石子对亚历克斯来说是一个胜利的举动,所以我们返回 true 。
2
3
4
5
6
7
8
提示:
2 <= piles.length <= 500piles.length是偶数。1 <= piles[i] <= 500sum(piles)是奇数。
# 第一版,看的解析,很厉害
https://leetcode-cn.com/problems/stone-game/solution/dong-tai-gui-hua-by-cliant/
动态规划+二维数组
判断的结果为先拿者是否可以拿到较多的石子。可以将问题转换为先拿者的石子数相对于后拿者的石子数的差值是否为正数,即表示先拿者的石子数是否多于后拿者的石子数。所以在依次拿石子的过程中,依次判断先拿者相对于后拿者的石子数即可。
不妨以 f(i,j)f(i,j) 表示对于下标 ii 到下标 jj 的 (j-i+1)(j−i+1) 堆石子,当前选手相对于对手能够多出的石子数。若 i==ji==j,则明显当前选手相对于对手多出的石子数为 f(i,j)=piles[i]f(i,j)=piles[i],因为只有一堆石子。
若有两堆或多堆石子,则 f(i,j)=max(piles[i]-f(i+1,j), piles[j]-f(i,j-1))f(i,j)=max(piles[i]−f(i+1,j),piles[j]−f(i,j−1)),其中 f(i+1,j)f(i+1,j) 表示对手相对于当前选手多出的石子,当前选手选择 piles[i]piles[i],所以当前选手相对于对手多出的石子为 piles[i]-f(i+1,j)piles[i]−f(i+1,j)。同理对于 piles[j]-f(i,j-1))piles[j]−f(i,j−1)) 。所以当前选手取两种情况中的最大值。
以 dp[i][j]dp[i][j] 二维数组存储 f(i,j)f(i,j) 的值,递推过程如下图所示:
因为初始情况只知道 i==ji==j ,即对角线上的 dpdp 值,所以推导 dpdp 数组按照红色序号顺序进行。
执行用时 :12 ms, 在所有 cpp 提交中击败了49.16%的用户
内存消耗 :17.1 MB, 在所有 cpp 提交中击败了20.00%的用户
bool stoneGame(vector<int>& piles) {
//dp[i][j]为i开始到j结束alex能赢li多少分 alex先拿的话
//dp[i][j] = max(piles[i]-dp[i+1][j],piles[j]-dp[i][j-1])(先拿左边的-对手比我多的,先拿右边的-对手比我多的)
int len = piles.size();
vector<vector<int>> dp (len,vector<int>(len,0));
for (int i = 0; i < len; i++) {
dp[i][i] = piles[i];
}
for (int i = 1; i < len; i++) {
for (int j = 0; j < len - i; j++) {
dp[j][j + i] = max(piles[j] - dp[j + 1][j + i], piles[j + i] - dp[j][j + i - 1]);
}
}
return dp[0][len - 1] > 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 降维处理
执行用时 :12 ms, 在所有 cpp 提交中击败了49.16%的用户
内存消耗 :8.2 MB, 在所有 cpp 提交中击败了96.80%的用户
bool stoneGame(vector<int>& piles) {
int len = piles.size();
vector<int> dp (piles);
for (int i = 1; i < len; ++i)
for (int j = 0; j < len - i; ++j)
dp[j] = max(piles[j] - dp[j + 1], piles[j + i] - dp[j]);
return dp[0] > 0;
}
};
2
3
4
5
6
7
8
9
10
11
# 931. 下降路径最小和 经典DP问题
力扣原题链接(点我直达) (opens new window)
给定一个方形整数数组 A,我们想要得到通过 A 的下降路径的最小和。
下降路径可以从第一行中的任何元素开始,并从每一行中选择一个元素。在下一行选择的元素和当前行所选元素最多相隔一列。
示例:
输入:[[1,2,3],[4,5,6],[7,8,9]]
输出:12
解释:
可能的下降路径有:
2
3
4
[1,4,7], [1,4,8], [1,5,7], [1,5,8], [1,5,9][2,4,7], [2,4,8], [2,5,7], [2,5,8], [2,5,9], [2,6,8], [2,6,9][3,5,7], [3,5,8], [3,5,9], [3,6,8], [3,6,9]
和最小的下降路径是 [1,4,7],所以答案是 12。
提示:
1 <= A.length == A[0].length <= 100-100 <= A[i][j] <= 100
# 第一版,标准DP做法
执行用时 :8 ms, 在所有 cpp 提交中击败了99.18%的用户
内存消耗 :10.1 MB, 在所有 cpp 提交中击败了33.33%的用户
int minFallingPathSum(vector<vector<int>>& A) {
int len = A.size();
vector<vector<int>> dp(len, vector<int>(len, 0));
for (int i = 0; i < len; ++i) {
dp[0][i] = A[0][i];
}
for (int i = 1; i < len; ++i) {
for (int j=0; j < len; ++j) {
if (j == 0)
{
dp[i][j] = min(dp[i - 1][j], dp[i - 1][j + 1]) + A[i][j];
}
else if (j == len - 1)
{
dp[i][j] = min(dp[i - 1][j], dp[i - 1][j - 1]) + A[i][j];
}
else
dp[i][j] = min(dp[i-1][j-1],min(dp[i - 1][j], dp[i - 1][j + 1])) + A[i][j];
}
}
//for (auto a : dp) {
// for (auto b : a) {
// cout << b << " ";
// }
// cout << endl;
//}
return *min_element(dp[len - 1].begin(), dp[len - 1].end());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 第二版,原地DP就行,节约空间
执行用时 :12 ms, 在所有 cpp 提交中击败了92.29%的用户
内存消耗 :9.6 MB, 在所有 cpp 提交中击败了99.15%的用户
int minFallingPathSum(vector<vector<int>>& A) {
int len = A.size();
for (int i = 1; i < len; ++i) {
for (int j=0; j < len; ++j) {
if (j == 0)
{
A[i][j] = min(A[i - 1][j], A[i - 1][j + 1]) + A[i][j];
}
else if (j == len - 1)
{
A[i][j] = min(A[i - 1][j], A[i - 1][j - 1]) + A[i][j];
}
else
A[i][j] = min(A[i-1][j-1],min(A[i - 1][j], A[i - 1][j + 1])) + A[i][j];
}
}
//for (auto a : dp) {
// for (auto b : a) {
// cout << b << " ";
// }
// cout << endl;
//}
return *min_element(A[len - 1].begin(), A[len - 1].end());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 1143. 最长公共子序列 经典
力扣原题链接(点我直达) (opens new window)
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。 例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回 0。
示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace",它的长度为 3。
2
3
示例 2:
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc",它的长度为 3。
2
3
示例 3:
输入:text1 = "abc", text2 = "def"
输出:0
解释:两个字符串没有公共子序列,返回 0。
2
3
提示:
1 <= text1.length <= 10001 <= text2.length <= 1000- 输入的字符串只含有小写英文字符。
# 第一版,DP解法,写错了
"bl"
** "yby"**
输出:0
预期:1
int longestCommonSubsequence(string text1, string text2) {
int len1 = text1.size(),len2=text2.size();
vector<vector<int>> dp(len1, vector<int>(len2, 0));
if (text1[0] == text2[0]) dp[0][0] = 1;
for (int i = 0; i < len1; ++i) {
for (int j = 0; j < len2; ++j) {
if (i == 0 || j==0 ) {
dp[i][j] = dp[0][0];
}else if(text1[i] == text2[j]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else {
dp[i][j] = max(dp[i-1][j],max(dp[i - 1][j - 1], dp[i][j - 1]));
}
}
}
return dp[len1-1][len2-1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 第二版,改了一下,有的想法没考虑到
执行用时 :20 ms, 在所有 cpp 提交中击败了69.48%的用户
内存消耗 :14.7 MB, 在所有 cpp 提交中击败了100.00%的用户
int longestCommonSubsequence(string text1, string text2) {
int len1 = text1.size(),len2=text2.size();
vector<vector<int>> dp(len1, vector<int>(len2, 0));
//if (text1[0] == text2[0]) dp[0][0] = 1;
//必须预先处理 0 0 的情况
for (int i = 0; i < len1; ++i) {
if (text1[i] == text2[0])
while (i < len1)
dp[i++][0] = 1;
else
dp[i][0] = 0;
}
for (int j = 0; j < len2; ++j) {
if (text2[j] == text1[0])
while (j < len2)
dp[0][j++] = 1;
else
dp[0][j] = 0;
}
for (int i = 1; i < len1; ++i) {
for (int j = 1; j < len2; ++j) {
if (text1[i] == text2[j]){
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else
dp[i][j] = max(dp[i - 1][j], max(dp[i - 1][j - 1], dp[i][j - 1]));
//cout << i << " " << j << " " << dp[i][j] << endl;
}
}
return dp[len1-1][len2-1];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 第三版,别人的解法,他多开辟一个空间,慢一些,但是也更加容易理解一些
执行用时 :24 ms, 在所有 cpp 提交中击败了41.77%的用户
内存消耗 :14.8 MB, 在所有 cpp 提交中击败了100.00%的用户
int longestCommonSubsequence(string text1, string text2) {
int len1 = text1.size(),len2=text2.size();
vector<vector<int>> dp(len1+1, vector<int>(len2+1, 0));
for (int i = 1; i <= len1; ++i) {
for (int j = 1; j <= len2; ++j) {
if (text1[i-1] == text2[j-1]){
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
//cout << i << " " << j << " " << dp[i][j] << endl;
}
}
return dp[len1][len2];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 二刷:
执行用时:32 ms, 在所有 C++ 提交中击败了64.01%的用户
内存消耗:12.9 MB, 在所有 C++ 提交中击败了51.16%的用户
int longestCommonSubsequence(string text1, string text2) {
int len1 = text1.size(), len2 = text2.size();
if (len1 == 0 || len2 == 0) return 0;
vector<vector<int>> dp(len1+1, vector<int>(len2+1, 0));// 以 dp[i][j] 以 text1【i】和text2[j]为结尾的字符串的长度最长公共子序列为多长
for (int i = 1; i <= len1; ++i) {
for (int j = 1; j <= len2; ++j) {
if (text1[i-1] != text2[j-1])
{
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
else {//当前元素相同
dp[i][j] = dp[i - 1][j - 1] + 1;
}
}
}
return dp[len1][len2];
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 1277. 统计全为 1 的正方形子矩阵 很好的题目
力扣原题链接(点我直达) (opens new window)
给你一个 m * n 的矩阵,矩阵中的元素不是 0 就是 1,请你统计并返回其中完全由 1 组成的 正方形 子矩阵的个数。
示例 1:
输入:matrix =
[
[0,1,1,1],
[1,1,1,1],
[0,1,1,1]
]
输出:15
解释:
边长为 1 的正方形有 10 个。
边长为 2 的正方形有 4 个。
边长为 3 的正方形有 1 个。
正方形的总数 = 10 + 4 + 1 = 15.
2
3
4
5
6
7
8
9
10
11
12
示例 2:
输入:matrix =
[
[1,0,1],
[1,1,0],
[1,1,0]
]
输出:7
解释:
边长为 1 的正方形有 6 个。
边长为 2 的正方形有 1 个。
正方形的总数 = 6 + 1 = 7.
2
3
4
5
6
7
8
9
10
11
提示:
1 <= arr.length <= 3001 <= arr[0].length <= 3000 <= arr[i][j] <= 1
# 1、经典DP + 剪枝
执行用时:136 ms, 在所有 C++ 提交中击败了85.93%的用户
内存消耗:18.8 MB, 在所有 C++ 提交中击败了50.00%的用户
int countSquares(vector<vector<int>>& matrix) {
int row = matrix.size();
if (row == 0) return 0;
int col = matrix[0].size();
int res = 0;
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
if (matrix[i][j] && i && j) {//直接将
// i=0,j=0,matrix[i][j] = 0这三种情况去除掉了
matrix[i][j] += min({matrix[i-1][j-1],matrix[i][j - 1], matrix[i - 1][j]});
}
res += matrix[i][j];
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 5454. 统计全 1 子矩形 超级好题
力扣原题链接(点我直达) (opens new window)
给你一个只包含 0 和 1 的 rows * columns 矩阵 mat ,请你返回有多少个 子矩形 的元素全部都是 1 。
示例 1:
输入:mat = [[1,0,1],
[1,1,0],
[1,1,0]]
输出:13
解释:
有 6 个 1x1 的矩形。
有 2 个 1x2 的矩形。
有 3 个 2x1 的矩形。
有 1 个 2x2 的矩形。
有 1 个 3x1 的矩形。
矩形数目总共 = 6 + 2 + 3 + 1 + 1 = 13 。
2
3
4
5
6
7
8
9
10
11
示例 2:
输入:mat = [[0,1,1,0],
[0,1,1,1],
[1,1,1,0]]
输出:24
解释:
有 8 个 1x1 的子矩形。
有 5 个 1x2 的子矩形。
有 2 个 1x3 的子矩形。
有 4 个 2x1 的子矩形。
有 2 个 2x2 的子矩形。
有 2 个 3x1 的子矩形。
有 1 个 3x2 的子矩形。
矩形数目总共 = 8 + 5 + 2 + 4 + 2 + 2 + 1 = 24 。
2
3
4
5
6
7
8
9
10
11
12
13
示例 3:
输入:mat = [[1,1,1,1,1,1]]
输出:21
2
示例 4:
输入:mat = [[1,0,1],[0,1,0],[1,0,1]]
输出:5
2
提示:
1 <= rows <= 1501 <= columns <= 1500 <= mat[i][j] <= 1
# 1、上面一题的进化版,竞赛题之一,太难了
执行用时:88 ms, 在所有 C++ 提交中击败了100.00%的用户
内存消耗:13.3 MB, 在所有 C++ 提交中击败了100.00%的用户
int numSubmat(vector<vector<int>>& mat) {
if (mat.size() == 0) return 0;
int row = mat.size(), col = mat[0].size();
int res = 0;
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++)
{
if (mat[i][j] == 0)
continue;
int col_max = col;//只统计当前位置右下方能组成的矩形
for (int m = i; m < row; m++) {
for (int n = j; n < col_max; n++) {
if (mat[m][n] == 0) {
col_max = n;//我真的服这种写法
break;
}
res++;
}
}
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 二刷:超越双百
int numSubmat(vector<vector<int>>& mat) {
if (mat.size() == 0) return 0;
int row = mat.size(), col = mat[0].size();
int res=0;
for(int i=0;i<row;++i){
for(int j=0;j<col;++j){
if(mat[i][j]==0) continue;
int count=0,colTemp = col;
for(int m=i;m<row;++m){
for(int n=j;n<colTemp;++n){
if(mat[m][n]==0) {
colTemp = n;
break;
}
count++;
}
}
res +=count;
// cout<<res<<endl;
}
}
return res;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28