读完两遍《STL源码剖析》后,我发现了一些辛秘
作者:阿秀
原文链接:https://mp.weixin.qq.com/s/vk3dpHrwQQJTfSLGf_xt9g (opens new window)
这是六则或许对你有些许帮助的信息:
⭐️1、阿秀与朋友合作开发了一个编程资源网站,目前已经收录了很多不错的学习资源和黑科技(附带下载地址),如过你想要寻求合适的编程资源,欢迎体验以及推荐自己认为不错的资源,众人拾柴火焰高,我为人人,人人为我🔥!
2、👉23年5月份阿秀从字节跳动离职跳槽到某外企期间,为方便自己找工作,增加上岸几率,跟朋友一起从0开发了一个互联网中大厂面试真题解析网站,包括两个前端和一个后端。能够定向查看互联网公司的笔试真题,比如我想查一下字节跳动近一年的笔试真题有哪些?都是可以做到的。欢迎体验~
网站地址:大厂面试算法真题网站。 3、😊 分享一个阿秀自己私藏的黑科技网站,点此直达,主要是各类小众实用APP、网站等,除此外也包括高清影视、音乐、电视剧、AI、纪录片、英语四六级考试、考研考公、副业等资源。4、😍免费分享阿秀个人学习计算机以来收集到的免费学习资源,点此白嫖;也记录一下自己以前买过的不错的计算机书籍、网络专栏和垃圾付费专栏;也记录一下自己以前买过的不错的计算机书籍、网络专栏和垃圾付费专栏
5、🚀如果你想在校招中顺利拿到更好的offer,阿秀建议你多看看前人踩过的坑和留下的经验,事实上你现在遇到的大多数问题你的学长学姐师兄师姐基本都已经遇到过了。
6、🔥 欢迎准备计算机校招的小伙伴加入我的学习圈子,一个人踽踽独行不如一群人报团取暖,圈子里沉淀了很多过去21/22/23/24/25届学长学姐的经验和总结,好好跟着走下去的,最后基本都可以拿到不错的offer!如果你需要《阿秀的学习笔记》网站中📚︎校招八股文相关知识点的PDF版本的话,可以点此下载 。
前排提醒
- 本文是阿秀以前给某位大佬投稿的文章改编而来,当时自己文笔还较弱,现重新改写润色一下发表出来,希望与大家共同进步!
- 阅读本文需要具备一些C++基础,不是面向小白的文章,可以说是又一篇干货。
- 因个人能力有限,如果总结的不到位,欢迎各位大佬在留言区批评指正。
# 前言
大家好,我是阿秀。
对于每一位学习 C++ 的小伙伴来说,STL 不可谓不重要,特别是那些为我们造好的底层轮子比如容器、算法等更是一件利器,比如在一些 OJ 平台,用 STL 下的算法刷题简直不要太爽,谁用谁知道。
不止如此,在一些大厂面试过程中,C++有两个区分度比较高的知识点:虚函数相关和 STL 。
不管是骡子是马,问一下这两个知识点就知道几斤几两了。
今天阿秀就带大家梳理一下 STL 中的常见容器下的一些小知识吧,都是我过去两年在学习C++过程中慢慢总结出来的。
在此过程中阿秀也带大家去动手检验一下,那些所谓的「定理」究竟是不是真理。
特别喜欢侯捷老师的一句名言:源码面前,了无秘密。

侯捷老师靓照镇楼
好了,发车!
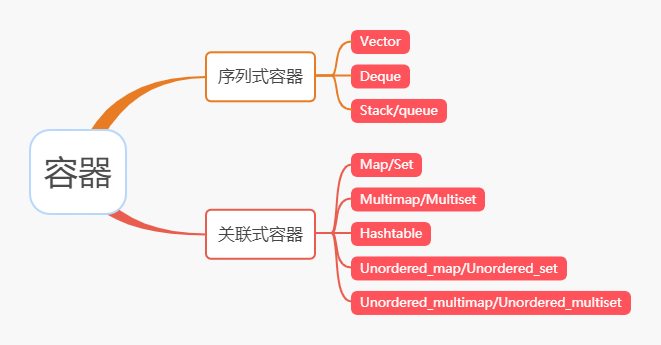
STL 下的容器主要分为两类:序列式容器以及关联式容器。
序列式容器顾名思义就是物理上彼此相邻的一种关系,比如数组、栈、队列或者你和你的同桌,这种一个挨着一个的关系;
关联式容器的重点在关联二字上,至少是两个东西之间存在着某种联系才可以叫做关联,否则就不能被称之为关联式容器了,比如 hashtable 中的 key 和 value,是一种一对一或者一对多的关系。
# 序列式容器
# vector
不知道在读的小伙伴在刷算法题的时候最喜欢哪个容器,我个人最喜欢的、用的最顺手的容器绝对是vector。
它是一种类似于数组的数据结构,它与数组 array 非常类似,两者的唯一差别就是对于空间运用的灵活性,vector 更加灵活多变,而 array 比较固定,具体来说:
- array 占用的是静态空间。也就是说一旦配置了它的空间就不可以改变大小,如果遇到空间不足的情况还要自行创建更大的空间,并手动将以前的数据拷贝到新的空间中,再把原来的空间释放才行。
- vector 则使用更加灵活的动态空间来进行配置。它始终维护一块连续的线性空间,在空间不足时,vector可以自动扩展空间容纳新元素,做到按需供给。其在扩充空间的过程中仍然需要经历:重新配置空间,移动数据,释放原空间等操作。
《STL源码剖析》一书中侯捷老师说 vector 扩容倍数为2倍,如下图所示:
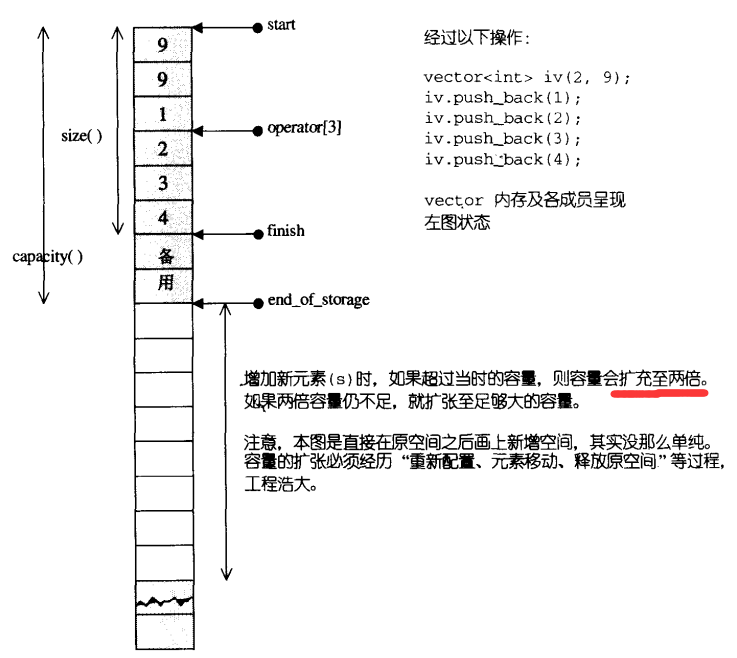
但网上也有说 1.5 倍的,后来我自己动手实践一番后得出结论:动态扩容原则跟操作系统相关,没有一个统一的结论,也就是说在不同环境下 vector 的扩容系数是不一样的,不可盖棺定论为 2 倍。
实践代码如下:
int main()
{
vector<int> data(2, 1);
cout << "size: " << data.size() << " capacity " << data.capacity() << endl;
data.push_back(1);
cout << "size: " << data.size() << " capacity " << data.capacity() << endl;
data.push_back(1);
cout << "size: " << data.size() << " capacity " << data.capacity() << endl;
data.push_back(1);
cout << "size: " << data.size() << " capacity " << data.capacity() << endl;
data.push_back(1);
cout << "size: " << data.size() << " capacity " << data.capacity() << endl;
data.push_back(1);
cout << "size: " << data.size() << " capacity " << data.capacity() << endl;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16

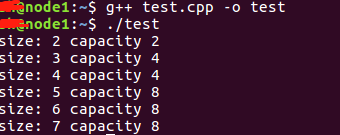
结论
- 在 Windows 10 + Visual Studio 2019 下的扩容倍数为 1.5 倍
- 在 Linux 与 g++ 环境下扩容倍数是 2 倍,其中Linux为 Ubuntu 18.04,g++版本为5.4.0
# deque
deque 与 vector 不同,vector维护的是单向开口(尾部)的连续线性空间,deque维护的则是一种双向开口的连续线性空间。
“
有一说一:vector其实也可以在联系空间的头尾进行操作,比如插入或者删除。但是因为涉及到 vector 内部已有元素的整体移动,所以其头部操作的效率十分低下。一般不建议在vector的头部进行元素的插入删除等操作。
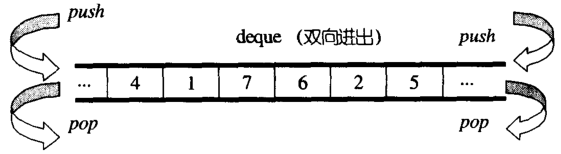
deque 和 vector的最大不同就是是deque没有容量的概念,它是动态地以分段连续空间组合而成,如下图所示。
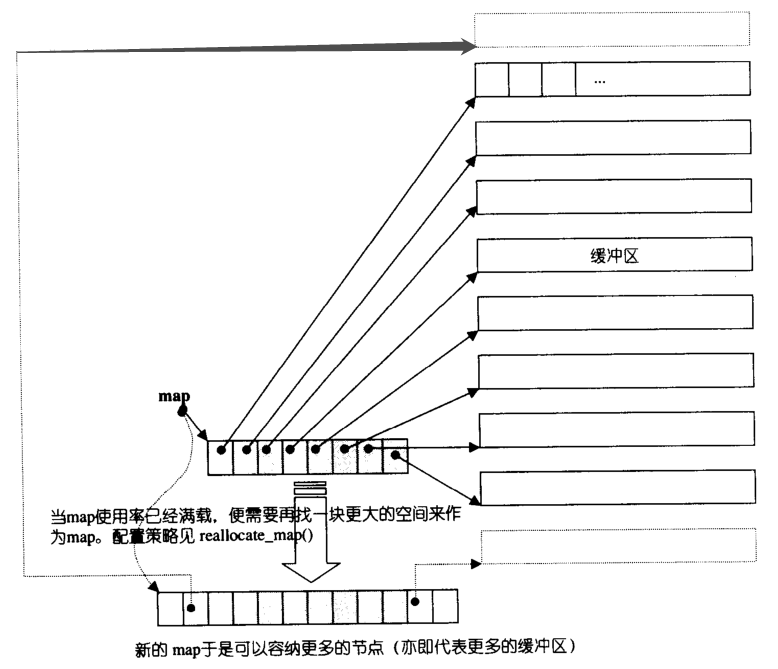
所以一旦需要增加新的空间,只要配置一段连续空间,然后将其拼接在头部或尾部即可,因此对于deque来说最重要的就是如何维护这个整体的连续性,关键点就在于 deque 的迭代器上,下面来看看 deque 是如何实现的:
deque的迭代器数据结构如下:
struct __deque_iterator
{
...
T* cur;//迭代器所指缓冲区当前的元素
T* first;//迭代器所指缓冲区第一个元素
T* last;//迭代器所指缓冲区最后一个元素
map_pointer node;//指向map中的node
...
}
2
3
4
5
6
7
8
9
从 deque 的迭代器数据结构可以看出,为了保持与容器联结,迭代器主要包含四个主要部分:T* cur ,迭代器所指缓冲区当前的元素; T* first,迭代器所指缓冲区第一个元素;T* last,//迭代器所指缓冲区最后一个元素 ;map_pointer node , 指向map中的node,其结构图如下图所示:
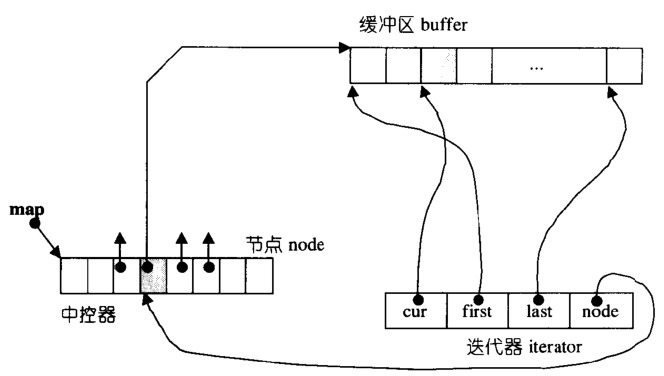
deque迭代器的迭代器主要关注缓冲区边界是否越界。比如 deque 进行自增 或者 自减 操作时,首先要检查的是当前cur递增或者递减后的结果是否已经越界,如果越界需要对 node 进行相应的处理,比如指向前一个缓存区或者指向后一个缓冲区等;如果没有越界就可以指向当前缓冲区的上一个或者下一个空间了。
# stack/queue
“stack和queue应该被称作是适配器,因为 satck/queue 都是在别的容器基础上进行修改,提供某些特定的接口而形成的“新型容器”。
stack 是一种先进后出的数据结构,只能通过栈顶来进行元素的获取或者删除,没有其他办法对内部元素进行操作,当然也没有迭代器。其结构图如下:

stack 这种单向开口的“新型容器”底层容器是双向开口的 deque 和 list ,然后逐渐移除某些功能接口即可实现,stack的部分源码如下:
template <class T, class Sequence = deque<T> >
class stack
{
...
protected:
Sequence c;
public:
bool empty(){return c.empty();}
size_type size() const{return c.size();}
reference top() const {return c.back();}
const_reference top() const{return c.back();}
void push(const value_type& x){c.push_back(x);}
void pop(){c.pop_back();}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
值得注意的是:stack 的默认 Sequence 是 deque,如果你想要自己指定 list 为 Sequence 也是可以的。
queue(队列)是一种先进先出的数据结构,可以在队首或者队尾进行某些操作来改变队列,它跟stack类似,也没有其他方法可以获取到内部的其他元素,换句话说也是不提供迭代器的。其结构图如下:
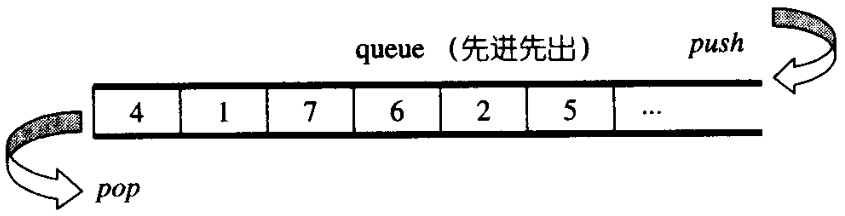
跟stack一样,queue 的默认Sequence也是 deque,如果你想要自己指定 list 为 Sequence 也是可以的。
其部分源码如下:
template <class T, class Sequence = deque<T> >
class queue
{
...
protected:
Sequence c;
public:
bool empty(){return c.empty();}
size_type size() const{return c.size();}
reference front() const {return c.front();}
const_reference front() const{return c.front();}
void push(const value_type& x){c.push_back(x);}
void pop(){c.pop_front();}
...
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 关联式容器
# map/set
map 中所有的元素都是pair类型,是一种所有元素会根据键值进行自动排序的数据结构。它拥有键值(key)和实值(value)两个部分,这是一种一对一的关系。一旦 map 的 key 确定了,那么这个 key 就是无法修改的,我们可以根据 key 找到 value 值,进而修改这个 key 对应的 value 值。
map的架构如下图所示:
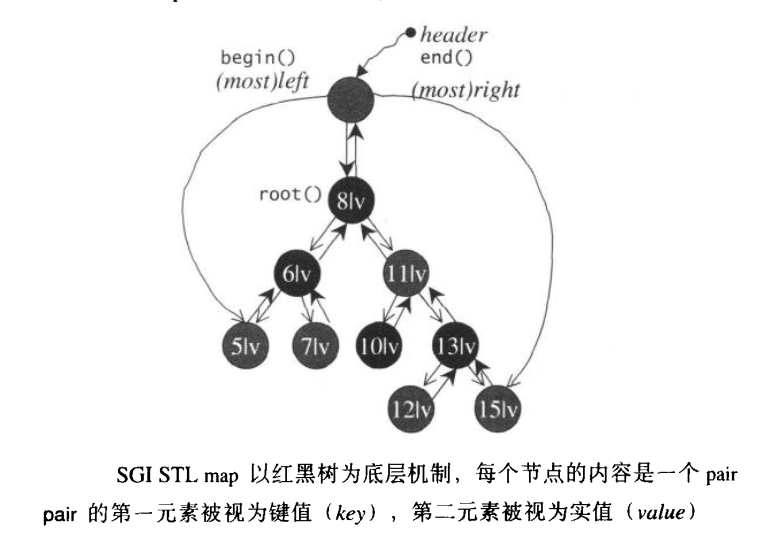
值得注意的是map的在构造时,默认是采用递增的规则来对 key 进行排序的。在插入元素时,map 调用的是红黑树中的 insert_unique() 函数,而非 insert_euqal()函数。
两者区别如下:
- insert_unique():这是一种独一无二的插入,就如同函数名一样。如果当前 map 中如果有一样的元素时,是无法插入成功的,只有当 map 中没有预插入的元素时,才能够插入成功,这也是从源码的角度保证:一个key值对应且只对应一个value。
- insert_euqal():这是一种相等的插入,就如同函数名一样。如果当前 map 中如果有一样的 key 时,是可以插入成功的,该函数主要用于multimap中,一个key值可以对应多个value值。
下面我们从代码角度验证 map 的默认排序规则
#include <iostream>
#include <map>
using namespace std;
int main()
{
map<int,int> data;
data.insert({ 2,2 });
data.insert({ 1,1 });
data.insert({ 3,3 });
data.insert({ 0,0 });
for (auto it = data.begin(); it != data.end(); ++it) {
cout << it->first << " " << it->second << endl;
}
return 0;
}
结果:0 0
1 1
2 2
3 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
由上述代码可以看出,我们在插入顺序是{2,2}、{1,1}、{3,3}、{0,0}。
在借助迭代器进行输出时,却按照key值升序的顺序输出的即{0,0}、{1,1}、{2,2}、{3,3},说明 map 确实是默认按照 key值升序 进行排列的。
在set中,所有元素都会根据元素的值自动被排序(默认升序),这一点跟 map 是一样的。set元素的 key 值就是 value 值,value 值就是key 值,set不允许有两个相同的键值,这是因为在底层实现上,set就只提供了 一个元素类型 的接口,是的,人家直接从源码角度给你限定死。
如下图所示:

可以看出identity函数其实就是一个将输入数据原样返回一个函数,换句话说输入是什么输出就什么。
这也就从源码角度上说明了为什么set的key和value值是一样的,那是因为在实现上,使用的函数功能就是输入是什么,输出就是什么。
set也不允许迭代器修改元素的值,其迭代器是一种constance_iterators,并不具备修改的功能。
set与 map 的底层数据结构都是 rb_tree(红黑树),只是对 rb_tree 进行二次封装,修改他的某些接口后形成的具有新特性的容器而已,就如同前文中提到的stack/queue 对 deque进行二次封装一样。
小结
set只提供一种数据类型的接口,但是会将这一个元素分配到key和value上,而且 compare_function() 用的是 identity()函数,这个函数是输入什么输出就是什么,这样就实现了set机制,所以set的 key值 和 value 值其实是一样的了。
其实它保存的是两份元素,而不是只保存一份元素。
map则提供两种数据类型的接口,分别放在key和value的位置上,他的 compare_function() 采用的是红黑树的compare_function(),保存的确实是两份元素。
接下来我们来用代码进行验证:
#include <iostream>
#include <map>
#include <set>
using namespace std;
int main()
{
set<int> st;
st.insert(1);
cout << "只有一个int型元素的set的大小:"<<sizeof(st) << endl;
map<int, int> mp;
mp.insert({1,1});
cout << "只有一个int型元素的map的大小:" << sizeof(mp) << endl;
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15

可以看出,set和map都只是保存了一份元素,前者保存了 1,而后者保存了 {1:1},同等情况下,set 与 map 所占内存大小是一样的。
所以并不是 set 保存的数据看起来好像少一个,那么它在同等情况下占的内存就少一些的,其实保存的都是两份元素。
我在做完这个试验之后也被震惊到了,原来好多博客上都是骗人的....
# multimap/multiset
multimap和map的唯一区别就是:multimap调用的是红黑树的 insert_equal() 方法,可以实现元素的重复插入。而map调用的则是独一无二的插入 insert_unique(),只能插入不同的数据。
multiset和set也一样,底层实现都是一样的,只是在插入的时候调用的方法不一样,前者调用的是红黑树的insert_equal(),后者调用的则是独一无二的插入insert_unique()。
# hashtable
常见的哈希冲突的解决方法有五种,分别是线性探测法、开链法、再散列法、二次探测法、公共溢出区(频率较低)
而 STL 采用的是开链法即每个表格维护一个list,如果hash函数计算出的格子相同,则按顺序存在这个list中。
如下图所示。
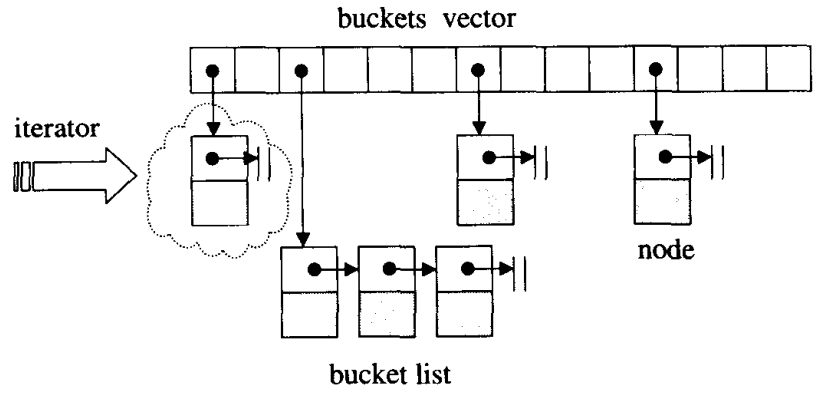
hashtable 中的 bucket 是自己定义的,一种由 hashtable_node 的数据结构组成的 linked-list,并不是简单的list或者双向list,而 bucket 采用 vector 来进行存储。
而在 bucket 的数量选择上,侯捷老师曾在《C++内存管理以及STL剖析视频》中提到过:hashtable在设计之初内置了 28 个质数[53, 97, 193,...,429496729]。
在创建 hashtable 时,会根据存入的元素个数选择不小于元素个数的那个质数来作为 hashtable 的容量(也就是bucket vector的长度),其中每个bucket所维护的 linked-list 长度也等于hashtable的容量。
如果插入 hashtable 的元素个数超过了 bucket 的容量,就要进行重建table操作,即找出下一个质数,创建新的buckets vector,重新计算元素在新 hashtable 的位置。
# 花絮
写到这里我想起来一件事情,去年我被某一线大厂面试官问过这样一个问题:“为什么 hashtable 中要内置 28 个质数,而第一个质数又为什么要从53开始?”
不得不说,这真是个2B好问题啊
针对这个问题,我记得我当时的回答大概是:“在我们日常生活中有一类问题,作为普通人的我们并没有那个能力或者经验去回答它或者解决它,我想也许是在以往的生产实践生活中,C++ 相关从业者慢慢发现hashtable的个数需要是质数,并且最小从 53 开始,最大为 429496729,C++相关的委员会也认可这种说法,就把哈希表定义成了现在这个样子。就好像你问我为什么 1+ 1 = 2一样,我也说不清为什么 1+ 1 = 2。”
# unordered_map/unordered_set
unordered_map/unordered_set 的底层使用的是 hashtable,而不是像 map/set 一样使用的红黑树,所以它没有自动排序功能,两者都是对 hashtable 进行二次封装形成的具有某些特性的新型容器。
这里可以参考 map 与 set 和红黑树的关系来理解 unordered_map 与 unordered_set 和 hashtable 的关系。
其中 unordered_map/unordered_set 的 insert函数() 都对 hashtable 的 insert_unique() 进行封装得到的,也就是独一无二的插入。
# unordered_multimap/unordered_multiset
unordered_multimap/unordered_multiset 的底层是使用的也是 hashtable,只不过这两者的 insert 函数是对hashtable 的 insert_equal() 进行封装得到的,也就是可以插入相同元素。
# 小结
map/set与multimap/multiset 都是以红黑树 rb_tree 为底层数据结构,区别就在于 map/set 调用的是红黑树的insert_unique() 函数,也就是独一无二的插入功能,如果当前 map/set 中已有,则插入失败;
而 multimap/multiset 调用的是红黑树的 insert_equal() 函数,也就是可重复性插入,如果当前map/set中已有,则插入成功。
unordered_map/unordered_set 与 unordered_multimap/unordered_multiset 都是以哈希表 hashtable 为底层数据结构,区别就在于 unordered_map/unordered_set 调用的是哈希表的 insert_unique() 函数,也就是独一无二的插入,如果当前unordered_map/unordered_set中已有,则插入失败;
而 unordered_multimap/unordered_multiset 调用的是 hashtable 的 insert_equal() 函数,也就是可重复性插入,如果当前unordered_map/unordered_set 中已有,则插入成功。
# 总结
侯捷老师的著作不可能只用短短一篇文章就囊括在内,具体的技术细节还是需要深入到书籍中去,本文只是做一点小小的总结和概括。
又是一篇八千字长文,码字不易!求个三连不过分吧?
最后,C++是世界上最好的语言,不接受反驳!

巨人肩膀
- 《STL源码剖析》
- 《C++Primer 5th》